一、 Hadoop技术介绍 在当今的数据爆炸的时代,随着云计算应用和互联网技术的发展,大数据已逐渐渗入到社会生活的方方面面。数据的不断增长创造了巨大的价值,也给质检机构的发展带来巨大的挑战。质检机构承担着社会质量监督检验的职责,其产生的质量数据是非常庞大的,如何应用这些海量数据的价值是质监信息化热切关注的问题。 Hadoop是Apache基金提供的分布式系统基础架构,广泛应用于海量数据存贮与分析处理领域。许多大型互联网公示都采用Hadoop进行大数据的存储和分析应用。Hadoop大数据是服务器软件所记录的用户访问系统的行为数据,其中包括用户的IP地址、访问时间等多种用户访问信息,如何将这些日志数据转化为适合进行数据挖掘与模式发现的标准会话文件,是Hadoop大数据的主要工作。 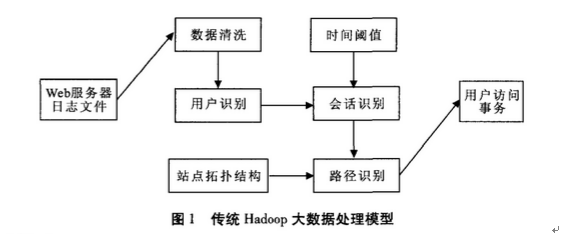
Hadoop的核心技术是MapReduce分布式数据处理模式和HDFS(Hadoop Distributed File System)分布式文件系统。基于MapReduce编写的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。HDFS能够将文件分隔成一个或多个块存储在一组数据节点中,数据节点维护中个文件系统树及树内所有文件和引索目录,同时记录着块与数据节点的映射关系。 二、 Hadoop在质检机构中的应用 1. 数据层 Hadoop数据层的工作主要包括数据采集和过滤。对采集到的质量数据进行筛选过滤,通常利用各种环境和生态信息进行提取,主要原因有:1)许多产品的质量通常会受到生产条件影响;2)产品在物流过程中的环境也会影响到产品的质量;3)食品等产品易受气候温度的影响。上述的各种信息均可从质量数据库或网络中获取,通过数据分析平台进行数据采集过滤存储等操作,利用专业人员的质量判别经验,满足数据采集的各种需求。 2. 数据处理层 此层的主要任务是分析数据层处理后的结果,对产品质量进行评估。本文设定关联模型作为核心评估技术,定义如下: 设定不同时间地点的各种气象生态信息的数据向量为X,茶叶质量数据向量为Y,其中(X,Y)=X∪Y,任意向量M(X,Y),其中Supp(M)=Count(M)为M支持度,M在向量集合{(X,Y)}中的出现次数使用Count(M)表示;对任意向量,此外我们定义X→Y的关联可信度为Conf(X→Y)/Supp(X);2)设可信度阈值为λ,定义关联规则集合为{X→Y} kk={X,Y},where Conf(X→Y)≥λ。该模型的执行流程为:1)通过数据层对各种数据向量{(X,Y)}集进行过滤分析;2)设置阈值λ,计算规则集合{X,Y},其中的{X}为条件集合;3)假设当前需要评估的的条件数据为x,首先计算x与集合{X}的各个向量的Jaccard相似度sim(x,X)= ,并记X为使得sim(x,X)=min{sim(x,X)}的条件向量;4)取满足规则(X→Y)∈{X→Y}的Y,即为评估预测结果。 数据处理层是基于MapReduce和Hadoop框架云计算平台,通过并行处理技术降低成本投入,使单个节点能够高效的进行数据处理任务。 3.管理层 管理层基于SOA思想进行设计,面向需求的精准服务,能够方便的和移动设备进行相互访问,使用大数据工作流的方式挖掘需要的数据信息。 三、 总结 运用Hadoop大数据技术能够监控预测产品的质量规律。在检验检测过程中,结合专业人员的分析方法,能够有效提高分析预测的成果。随着大数据技术的发展,建设大数据质量平台是十分必要的。数据积累是漫长的过程,在数据量不足的情况下很难得到准确的结果。因此当前质检机构应完善数据平台的采集功能,以积累更多数据。 |
